tsuNAME: DNS-lussen zijn een bekend probleem, maar worden nog niet helemaal opgelost door bestaande RFC’s
Recursieve resolvers zouden verkeerd geconfigureerde DNS-records die naar elkaar verwijzen moeten cachen
Recursieve resolvers zouden verkeerd geconfigureerde DNS-records die naar elkaar verwijzen moeten cachen

Auteurs: Giovane Moura (1,2), Sebastian Castro (3), John Heidemann (4) en Wes Hardaker (4) (1) SIDN Labs, (2) TU Delft, (3) InternetNZ, (4) USC/ISI
De oorspronkelijke blog is in het Engels. Dit is de Nederlandse vertaling.
Afgelopen mei traden we naar buiten met tsuNAME, een kwetsbaarheid in het DNS waarbij resolvers, clients en/of forwarders non-stop query’s naar autoritatieve DNS-servers sturen en zo DDoS-aanvallen kunnen veroorzaken. Hoewel eerdere RFC’s het bestaan van lussen tussen DNS-namen hebben gedocumenteerd, heeft geen daarvan het probleem helemaal opgelost. Om dat te verhelpen, hebben we een nieuwe IETF-draft ingediend bij de DNS Operations Working Group (DNSOP WG).
Een lus is een bekend type configuratiefout in DNS-zones, die al in de oorspronkelijke RFC 1034 (‘Domain Names – Concepts and Facilities’, november 1987) werd gedocumenteerd. Een CNAME-lus kan bijvoorbeeld als volgt worden gecreëerd:
.org zone file: example.org CNAME example.nl .nl zone file: example.nl CNAME example.org
In het bovenstaande voorbeeld kan een DNS-resolver geen van beide domeinen omzetten naar een IP-adres, omdat ze allebei naar elkaar verwijzen.
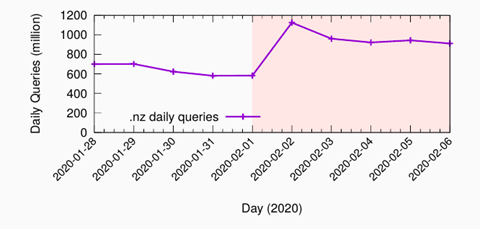
We ontdekten dat domeinnamen die zijn geconfigureerd met naar elkaar verwijzende nameserverrecords, ervoor kunnen zorgen dat resolvers aan één stuk door query’s naar autoritatieve servers blijven sturen. Hierdoor worden deze servers uiteindelijk overspoeld– wat de reden is dat we de kwetsbaarheid tsuNAME noemen. Dit gebeurde daadwerkelijk met de autoritatieve .nz-servers van Nieuw-Zeeland, toen twee verkeerd geconfigureerde namen met weinig verkeer ervoor zorgden dat het totale serververkeer ineens met de helft toenam (zie figuur 1).

Figuur 1: Autoritatieve .nz-servers zien verkeer met 50% toenemen tijdens tsuNAME-incident veroorzaakt door 2 domeinnamen.
De vraag is dan ook: als we er al zo lang vanaf weten, waarom zijn DNS-lussen dan nog steeds een probleem?
De eerste oplossing werd aangedragen in RFC 1034, waarin staat dat CNAME-lussen moeten worden ‘signalled as an error’ (paragraaf 3.6.2). Om te voorkomen dat resolvers bij configuratiefouten in een oneindige lus terechtkomen, adviseert RFC 1034 verder om een limiet te stellen aan het aantal query’s dat een resolver verstuurt bij het omzetten van een individuele domeinnaam.
RFC 1035 (‘Domain Names – Implementation and Specification’) stipuleert dat resolvers tellers moeten gebruiken om die limieten te implementeren. Later stelt RFC 1536 (‘Common DNS Implementation Errors and Suggested Fixes’) dat ‘a set of servers might form a loop wherein A refers to B and B refers to A’. Welke soorten records zo’n lus kunnen creëren vermeldt de RFC echter niet en ook andere oplossingen dan al werden gesuggereerd door RFC 1034 en RFC 1035 ontbreken.
Kortom, RFC 1034, RFC 1035 en RFC 1536 beschrijven het probleem en geven ook richtlijnen voor de implementatie van resolvers om oneindige lussen door verkeerd geconfigureerde zonefiles met NS- of CNAME-lussen te voorkomen. Toch blijft het probleem zich in verschillende vormen voordoen en daarom proberen we die richtlijnen in deze blog aan te scherpen.
We constateerden in onze onderzoekspaper dat zich verkeerspieken kunnen voordoen als er NS-lussen ontstaan:
Bij recursieve resolvers: hierbij gaat het om resolvers die aan één stuk door query’s naar autoritatieve servers blijven sturen na ontvangst van een enkele clientquery (figuur 1) voor een domein met een NS-lus. Deze recursieve resolvers voldoen niet aan de richtlijnen in RFC 1034 en RFC 1035, die allebei limieten stellen aan het aantal query’s dat een resolver mag versturen bij het omzetten van een DNS-naam.
Bij clients, stub resolvers en forwarders: er kunnen ook problemen ontstaan als delen van de DNS-infrastructuur achter een recursieve resolver non-stop query’s blijven sturen als gevolg van een NS-lus. De query’s komen aan bij hun upstream recursieve resolvers, die op hun beurt query’s naar autoritatieve servers sturen (en die zelf de stroom van query’s verder kunnen doen toenemen).
Bestaande RFC’s dragen oplossingen aan die voorkomen dat resolvers in een lus terechtkomen (hoewel we 2 oude versies van populaire DNS-software hebben gevonden die deze oplossingen niet implementeren). Telkens als een client een query naar de recursieve resolver stuurt, moet de resolver een SERVFAIL naar de client terugsturen als er nameserverrecords worden gedetecteerd die naar elkaar verwijzen – waarbij de in eerdere RFC’s geadviseerde tellers zorgen voor de detectie hiervan.
Maar dit voorkomt nog steeds niet dat clients, stubs en DNS-forwarders steeds opnieuw dezelfde vraag stellen. Stel dat een resolver staat ingesteld op 20 query’s als bovengrens voor het omzetten van een DNS-naam voordat het een SERVFAIL retourneert, zoals bij een lus. In dat scenario zal elke nieuwe query van elke client 20 nieuwe query’s teweegbrengen. Dat is precies het probleem dat we aantroffen in de implementatie van Google Public DNS: de bron van de lussen was niet de Google-resolversoftware, maar de clients die non-stop dezelfde query naar de resolver stuurden.
Om dit probleem op te lossen, bevelen we aan dat recursieve resolvers verkeerd geconfigureerde DNS-records die naar elkaar verwijzen moeten (MUST) cachen. Als een resolver dan een SERVFAIL terugstuurt naar een client, kunnen alle daaropvolgende query’s van clients rechtstreeks vanuit de cache van de resolver worden beantwoord. Zo ontstaat er dus een barrière tussen de resolver en clients die terecht zijn gekomen in een lus, wat uiteindelijk voorkomt dat overmatig verkeer autoritatieve servers bereikt.
Hoelang de naar elkaar verwijzende records in de cache moeten worden geplaatst, is een implementatiekeuze. Een recursieve resolver moet (MUST) echter minimaal 15minuten vanuit de cache antwoorden, gezien het feit dat de meeste situaties waarin NS/CNAME-records een lus veroorzaken menselijk ingrijpen vereisen.
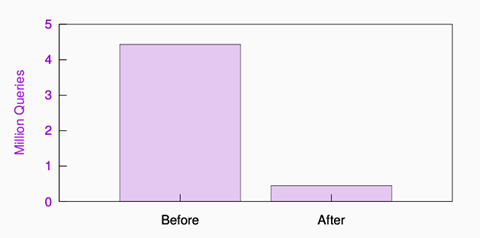
Google Public DNS heeft deze oplossing geïmplementeerd en zodra ze begonnen met het cachen van records die een lus veroorzaakten, was het probleem verholpen (zie figuur 2).

Figuur 2: Oplossing voor tsuNAME op Google Public DNS: aanzienlijke daling in queryvolumes na het cachen van records die een lus veroorzaken. Zie ons onderzoekspaper voor meer informatie.
We hebben dit voorstel afgelopen november in de vorm van een IETF-draft voorgelegd aan de DNSOP WG. We hebben er inmiddels feedback op gekregen en zullen binnenkort een bijgewerkte versie indienen. Wie meer wil weten over de specifieke kenmerken van tsuNAME, verwijzen we naar het onderzoekspaper die we presenteerden op ACM Internet Measurement Conference (IMC 2021) en de bijbehorende videopresentatie.





{kind=link}
{kind=link}