Breed gedistribueerde DNS-implementaties monitoren: uitdagingen en aanbevelingen
Het rootserversysteem als use case onder de loep genomen
Het rootserversysteem als use case onder de loep genomen

De oorspronkelijke blog is Engelstalig. Dit is de Nederlandse vertaling ervan.
DNS-nameservers zijn cruciaal voor de bereikbaarheid van domeinnamen. Daarom werken nameserveroperators met meerdere nameservers en repliceren en distribueren ze elke server vaak over verschillende locaties over de hele wereld. Operators monitoren de nameservers om te controleren of ze voldoen aan de verwachte prestatievereisten. Dit kan van binnenuit het systeem worden gedaan, bijvoorbeeld met metrics zoals CPU-gebruik, en van buitenaf, door de ervaring van de clients na te bootsen. In dit artikel richten we ons op het laatste. We nemen het rootserversysteem als use case en belichten de uitdagingen waarmee operators en onderzoekers worden geconfronteerd wanneer ze sterk gedistribueerde DNS-implementaties van buitenaf monitoren. Ook doen we aanbevelingen voor het construeren van een monitoringsysteem dat betrouwbaarder is en alleen de relevante metrics registreert.
Het DNS is een uitstekend voorbeeld van een gedecentraliseerd en gedistribueerd systeem. Zo is het een gedecentraliseerd systeem in de zin dat SIDN verantwoordelijk is voor .nl, Verisign voor .com en jij, de lezer, voor je eigen domeinnamen. Daarnaast is het een gedistribueerd systeem omdat elk van deze operators een geografisch verspreide verzameling autoritatieve nameservers gebruikt om informatie te verstrekken over hun deel van de namespace.
De meest gedistribueerde en gedecentraliseerde dienst in het DNS is waarschijnlijk de rootzone. Het rootserversysteem bestaat uit 13 verschillende nameservers, die worden beheerd door 12 verschillende organisaties en allemaal bereikbaar zijn via IPv4 en IPv6. 'Onder de motorkap' bestaan de nameservers uit meer dan 1.900 'sites' (fysieke of virtuele machines) gevestigd in netwerken over de hele wereld. De rootserveroperators (RSO's) maken hiervoor gebruik van een techniek die 'anycast' wordt genoemd. Het routeringsprotocol van het internet (BGP - Border Gateway Protocol) zorgt ervoor dat query's naar een bepaalde rootserver naar de site worden gestuurd die zich qua topografische netwerkafstand het dichtst bij de machine bevindt die het verzoek heeft verzonden.
Het rootserversysteem verstrekt informatie over alle autoritatieve nameservers voor TLD's, zoals .nl, en fungeert daarnaast als trust anchor voor de DNS-beveiligingsextensies (DNSSEC). En ook al stuurt een resolver in de loop van een dag relatief weinig query's naar de rootservers, als zich onverhoopt een grootschalige storing van de rootservers mocht voordoen, heeft dat uiteindelijk gevolgen voor de bereikbaarheid van alle domeinnamen ter wereld.
Een groep gedistribueerde DNS-servers van binnenuit monitoren (endogene monitoring) is betrekkelijk eenvoudig en gebeurt op basis van metrics van zowel individuele serverinstanties als het systeem als geheel. Basisvoorbeelden zijn CPU- en geheugengebruik, het aantal ontvangen query's per seconde en het serienummer van de zone die op dat moment wordt verstrekt. Meer geavanceerde metrics zijn onder meer of resolvers hun dichtstbijzijnde anycast-site bereiken en hoelang het duurt voor verzoeken bij de nameserver aankomen.
Door alleen op interne monitoring te vertrouwen, kunnen operators echter over het hoofd zien hoe hun clients de service ervaren. In het DNS levert monitoring van buitenaf (exogene monitoring), waarbij gebruik wordt gemaakt van vantage points die echte clients nabootsen, waardevolle inzichten op. Het kan bijvoorbeeld problemen op het netwerkpad naar een nameserver aan het licht brengen, ondersteuning bieden bij operationele wijzigingen en zichtbaar maken of derden zich proberen te bemoeien met de informatie die door de nameserver wordt verstrekt.
Tot slot stelt externe monitoring anderen in staat om openbare DNS-diensten zelfstandig te monitoren. Dit is waar de rootservers weer in beeld komen. Zoals hierboven beschreven, speelt het rootserversysteem een belangrijke rol binnen het DNS. Het is dan ook in het belang van de internetgemeenschap dat de rootservers te allen tijde beschikbaar zijn en naar behoren functioneren. Op dit moment zijn de enige standaard operationele gegevens voor het rootserversysteem de RSSAC002-gegevens, die op vrijwillige basis door RSO's worden verstrekt. Het ICANN Root Server System Advisory Committee (RSSAC) heeft RSSAC047 ontwikkeld voor gebruik door een toekomstig bestuursorgaan voor het rootserversysteem, waaronder RSO's mogelijk moeten voldoen aan contractuele verplichtingen voor prestaties, beschikbaarheid en kwaliteit van dienstverlening.
.nl vertrouwt op 3 nameservers die samen het .nl-nameserversysteem vormen. In totaal bestaat het nameserversysteem uit meer dan 80 sites gevestigd in netwerken over de hele wereld.
Voor de externe monitoring van de .nl-nameservers maakt SIDN ook gebruik van de metingen van RIPE Atlas. Net als de rootservers worden onze nameservers regelmatig bevraagd door alle RIPE Atlas probes. De metingen worden verwerkt en gepresenteerd op Grafana-dashboards binnen SIDN. Daarnaast maakt SIDN gebruik van op anycast gebaseerde prestatiemetingen die zijn verkregen met behulp van Verfploeter, een hybride tool voor externe en interne monitoring.
We raden je aan om onze blogpost over de DNS-infrastructuur voor .nl te lezen als je meer wilt weten.
RSSAC047v2 beschrijft de vereisten voor een monitoringsysteem voor de rootserver, inclusief de metrics die door het systeem moeten worden gecontroleerd. De metrics zijn zowel van toepassing op individuele rootservers als op het rootserversysteem als geheel.
Het gaat om de volgende metrics:
Beschikbaarheid: hoeveel tijd rootservers en het rootserversysteem niet bereikbaar zijn
Reactielatentie: de tijd die nodig is om op een query te reageren
Correctheid: of de servers reageren met de verwachte informatie
Publicatievertraging: de tijd die nodig is om de meest recente versie van de rootzone te verstrekken.
RSSAC047 beschrijft ook hoe metingen zouden moeten worden gecombineerd en welke prestatieniveaus worden verwacht.
Om bijvoorbeeld de beschikbaarheid van een rootserver te meten, moet het meetsysteem om de 5 minuten vanaf elk vantage point van de meting een SOA-query voor de rootzone versturen. Aan het einde van de maand berekent het meetsysteem het percentage query's waarop geen antwoord is gekregen (bijvoorbeeld omdat er een time-out is opgetreden). Als dat meer dan 4% is, geeft het meetsysteem aan dat de rootserver de gedefinieerde beschikbaarheidsdrempel niet heeft gehaald. Eens per maand wordt er een rapport gegenereerd waarin voor elke metric wordt samengevat hoe de rootservers en het rootserversysteem als geheel hebben gepresteerd.
ICANN heeft een initiële implementatie van de monitoringspecificaties ontwikkeld en houdt al meer dan 2 jaar toezicht op de hierboven vermelde metrics. De software is opensource.
De initiële implementatie bevindt zich momenteel nog in de ontwikkelingsfase en de gegenereerde rapporten zijn uitsluitend voor informatieve doeleinden. Dat neemt niet weg dat de gegenereerde rapporten herhaaldelijk niet overeenkwamen met de ervaring en verwachtingen van zowel operators als de gemeenschap. Ten eerste meldde de initiële implementatie verschillende keren dat het rootserversysteem de beschikbaarheidsdrempel niet haalde. Ten tweede verstrekte een van de rootletters in mei 2024 enkele dagen lang een verouderde rootzone, maar rapporteerde de initiële implementatie niets ongebruikelijks.
Naar aanleiding hiervan verzochten de RSO's Verisign en ISC ons en NLnet Labs om de implementatie en deployment van de meetsoftware en de verkregen metingen te onderzoeken. Het doel was om te achterhalen of het rootserversysteem daadwerkelijk ondermaats presteerde. Daar kwam bij dat in de loop van het onderzoek een van de rootservers er niet in slaagde om rootzones op tijd te publiceren. We wilden daarom ook nog uitzoeken waarom de meetsoftware geen melding maakte van de hoge publicatievertraging.
In de loop van het onderzoek hebben we verschillende uitdagingen geïdentificeerd waarmee bij externe metingen van de rootserversystemen rekening moet worden gehouden. Ook hebben we aanbevelingen geformuleerd voor hoe deze uitdagingen zouden kunnen worden aangepakt. Meer informatie over ons onderzoek kun je vinden in ons rapport.
We zijn van mening dat de inzichten die we hebben verkregen ook gelden voor monitoringsystemen voor andere gedistribueerde DNS-diensten. In de rest van dit artikel gaan we in op de algemene uitdagingen die we hebben geïdentificeerd en onze daarbij behorende aanbevelingen. We gebruiken ons onderzoek van het rootserversysteem ter illustratie.
De eerste grote uitdaging bij het meten van sterk gedistribueerde DNS-systemen is de selectie van vantage points. Wat RSSAC047 betreft, vertrouwt de initiële implementatie op 20 speciale vantage points op verschillende cloudplatforms en bij datacenters over de hele wereld.
Voor RSSAC047 was het doel een goede balans te vinden tussen dekking en beheersbaarheid. In het algemeen hebben operators van een monitoringsysteem echter de volgende 3 opties:
Bepalen welke sites het meest cruciaal zijn om te monitoren en proberen om vantage points te vinden waarmee deze kunnen worden bereikt.
Vantage points selecteren die een reflectie zijn van de meest 'belangrijke' clients.
Vantage points selecteren die gelijkmatig verdeeld zijn (bijvoorbeeld over een land, een continent of de wereld).
Er moet rekening mee worden gehouden dat routewijzigingen ervoor kunnen zorgen dat een vantage point niet altijd uitkomt op dezelfde site. Met behulp van de optie DNS Name Server Identifier (NSID) kan het meetplatform bijhouden op welke sites de verschillende VP's uitkomen.
Wat betreft de deployment van de initiële implementatie van de rootmonitoringsoftware ontdekten we dat het lage aantal vantage points ten opzichte van het aantal sites het vertrouwen in de meetresultaten verlaagde. Door de lage dekking werd de time-out van een bepaalde site op een bepaald tijdstip meestal door slechts 1 vantage point gemeten. Daardoor was het vaak onduidelijk of de time-out nou was veroorzaakt door de rootserversite, het netwerk of het vantage point zelf.
Daarnaast vonden we sterke aanwijzingen dat sommige vantage points zich bevonden op locaties met een slechte connectiviteit. Ze slaagden er bijvoorbeeld vaak niet in om alle rootservers tegelijkertijd te bereiken, wat een sterke indicatie is dat het vantage point of het netwerk van het vantage point de time-outs veroorzaakte en niet de rootservers.
De tweede grote uitdaging betreft de definitie van de metrics.
Dit werd duidelijk toen we de publicatievertraging onder de loep namen die voor een van de rootservers was gerapporteerd. We ontdekten dat het meetsysteem wel degelijk detecteerde dat er zonebestanden ontbraken, maar dat het probleem niet in de rapporten werd vermeld. De verklaring hiervoor ligt in de manier waarop de metingen worden geaggregeerd.
Volgens RSSAC047 wordt de maandelijkse publicatievertraging van een rootserver berekend door de mediaan te nemen van alle gemeten vertragingen. Zonebestanden die nooit zijn gepubliceerd, worden niet meegeteld. Deze metric is eenvoudig, maar heeft het nadeel dat problemen met zonepublicatie alleen worden gesignaleerd wanneer de vertraging minstens de helft van de maand hoog was.
Net als in het voorbeeld van RSSAC047 moeten metrics vaak een balans vinden tussen eenvoudig maar vaag en complex maar gedetailleerd. De metric voor publicatievertraging wordt op een heel eenvoudige manier berekend, maar dat brengt ook met zich mee dat er (belangrijke) details verloren gaan.
Operators en onderzoekers die sterk gedistribueerde systemen willen monitoren, worden ook geconfronteerd met uitdagingen waarin we in ons onderzoek geen aandacht hebben besteed. Voorbeelden hiervan zijn de kosten voor het monitoringplatform, de beschikbaarheid van vantage points op verschillende locaties en de meetfrequentie.
Op basis van onze analyse van de RSSAC047-metingen doen we 3 aanbevelingen voor het verbeteren van de monitoringsystemen van gedistribueerde DNS-systemen zoals de root.
Op de eerste plaats raden we aan om health checks van de vantage points te implementeren.
In het geval van RSSAC047 ontwikkelden we 2 extensies die we gedurende een proefperiode van 1 maand toepasten op de huidige implementatie.
Ten eerste hielden we vanaf een extra controleknooppunt de beschikbaarheid van de vantage points continu in de gaten. Hoewel ook deze metingen dubbelzinnig kunnen zijn (bijvoorbeeld door netwerkproblemen tussen het controleknooppunt en het vantage point), voegen ze 1 extra signaal toe dat kan helpen bij het interpreteren van de metingen door de vantage points.
Ten tweede voerden we traceroutemetingen uit die gericht waren op diensten die niet gerelateerd waren aan het rootserversysteem. De veronderstelling was dat als deze metingen op hetzelfde moment zouden mislukken als de rootservermetingen, dit een krachtig signaal zou zijn dat de connectiviteitsproblemen niet werden veroorzaakt door de rootservers.
Op de tweede plaats is het onze redenering dat het gebruik van meer vantage points het mogelijk maakt om een sterk gedistribueerd systeem nauwkeuriger te monitoren, ook al ontstaat er misschien meer ruis in het monitoringsysteem.
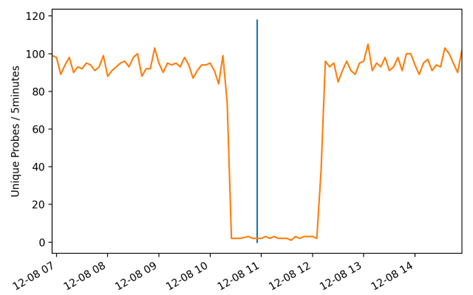
Om achteraf te testen of een time-out wel of niet werd veroorzaakt door de rootservers, maakten we gebruik van de metingen van meer dan 10.000 RIPE Atlas probes die om de paar minuten de rootservers bevragen. Als tientallen of honderden probes op hetzelfde moment connectiviteitsproblemen rapporteerden, lag het probleem hoogstwaarschijnlijk bij de rootserver. In de figuur hieronder zie je een voorbeeld waarin de initiële implementatie een time-out signaleerde (verticale blauwe lijn) en een groot aantal RIPE Atlas probes er niet in slaagde om bij dezelfde server te komen (oranje lijn). Dit was voor ons een krachtig signaal dat de meting van het VP te vertrouwen was en dat de rootserver of het pad naar de rootserver inderdaad niet beschikbaar was.

Figuur 1: Voorbeeld van een time-out waargenomen door de initiële implementatie (verticale lijn) die automatisch gecorreleerd is met een daling in de bereikbaarheid waargenomen door RIPE Atlas.
Door aanbevelingen 1 en 2 te implementeren konden we bevestigen dat de beschikbaarheid van het rootserversysteem zeer waarschijnlijk hoger was dan gerapporteerd door de initiële implementatie.
Onze derde aanbeveling is om testcases te ontwikkelen die operators helpen om metrics te bedenken die het ook echt mogelijk maken om verwachte storingen te rapporteren en om passende alarmdrempels te definiëren. Door testcases te ontwikkelen van storingen die wel en storingen die niet door de metric zouden moeten worden opgepikt, kunnen operators ervoor zorgen dat de metric alleen relevante situaties rapporteert.
In het voorbeeld van RSSAC047 hadden testcases waarin verschillende scenario's van vertraagde zonepublicatie werden gesimuleerd, RSSAC kunnen helpen om vast te stellen of de metric daadwerkelijk in staat was om relevante storingen weer te geven.
Hoe je een gedistribueerde DNS-dienst wilt monitoren hangt af van een groot aantal verschillende factoren: hoe grootschalig de dienst is, of je de dienst zelf beheert of niet, waarom je überhaupt wilt monitoren, en wat de doelgroep is van de rapporten die door het monitoringsysteem worden gemaakt. Dat geldt niet alleen voor de RSSAC047-metingen, maar ook voor andere platforms die gedistribueerde DNS-systemen monitoren.
In het geval van RSSAC047 zijn er al 2 iteraties nodig geweest om de metrics te verbeteren en waarschijnlijk volgt er nog een derde. We hopen dat ons onderzoek kan bijdragen aan de verdere verbetering van de metrics. Meer informatie over ons onderzoek kun je vinden op onze website. Ons rapport gaat ook dieper in op de broncode en beschrijft in detail hoe we tot de conclusie zijn gekomen dat de rootservers zeer waarschijnlijk beter presteren dan oorspronkelijk gerapporteerd.
We willen Verisign, ISC en ICANN bedanken voor hun ondersteuning tijdens dit onderzoek. Ook willen we de RSO's en de leden van de RSSAC-werkgroep bedanken voor hun feedback.
Wil je reageren op deze blogpost of ons rapport? Neem dan contact met ons op via moritz.muller@sidn.nl.






{kind=link}